
Introduction
Avant de configurer VXLAN, il faut comprendre comment il fonctionne. Comme évoqué dans le premier épisode, on peut résumer VXLAN à un protocole qui permet l'encapsulation au dessus d'IP. De ce fait, il transporte des trames de niveau 2. Qui dit niveau 2 dit adresses MAC.
Un équipement qui fait VXLAN est appelé VTEP. Un leaf, un ESXI, un proxmox peut être VTEP. Par contre, ce n'est pas le cas d'un spine.
Mais comment un VTEP pourrait apprendre une MAC d'une VM branchée sur un autre VTEP ? Comment il pourrait aussi annoncer une d'une autre VM ?
Pour répondre à ces 2 problématiques, on va utiliser EVPN. Défini dans la RFC 7432, on apprend que l'EVPN a été crée pour remédier aux limites de VPLS (multihoming et redondance, multicast, complexité, load-balancing et le multipath).
L'Ethernet VPN n'est pas un protocole mais plutôt une extension de BGP. C'est une address-family dans la configuration de BGP, comme c'est le cas pour l'ipv4, vpnv6 et autres. Il va alors permettre la diffusion des MACs (et plus !) dans la fabric VXLAN.
Le VXLAN est le data plane (plan de données en français, ca fait pas classe donc on va continuer à le dire en anglais !). C'est lui qui va transporter les données finales (communication entre 2 terminaux par exemple). Quant à l'EVPN, ça va être le control plane.
Mais c'est quoi le rapport avec l'underlay dans tout ça ? On s'en fiche du data et du control plane.
Et bah non ! On peut définir le couple VXLAN/EVPN comme l'overlay de la fabric. C'est l'association de ces deux technologies qui va permettre d'outrepasser les limites du niveau 2. Et pour que cet overlay fonctionne, il faut bien un underlay !
L'underlay a une et une seule mission : permettre la connectivité IP entre les leafs et les spines pour établir les sessions BGP pour l'EVPN.
Plutôt facile nan ? Il suffit de mettre en place un protocole de routage et hop l'affaire est dans le sac.
Quels sont nos besoins ?
- Chaque Spine doit avoir une loopback (Pour le control plane)
- Chaque Leaf doit avoir deux loopback (Une pour le control plane et une pour le data plane)
Assez simple nan ? Mais entre OSPF, IS-IS, RIP et BGP, qui choisir ?
Je suis parti sur l'eBGP. Ce blog ne tend pas à justifier le choix. Aujourd'hui, tous les protocoles de routages peuvent répondre à ces besoins surtout dans le cas d'une petite fabric comme la nôtre. Ma seule explication serait que j'ai trouvé ça stylé d'avoir le même protocole utilisé pour l'underlay et l'overlay 😝 (et ca doit être la bonne pratique pour Arista vu la documentation à ce sujet).
MLAG
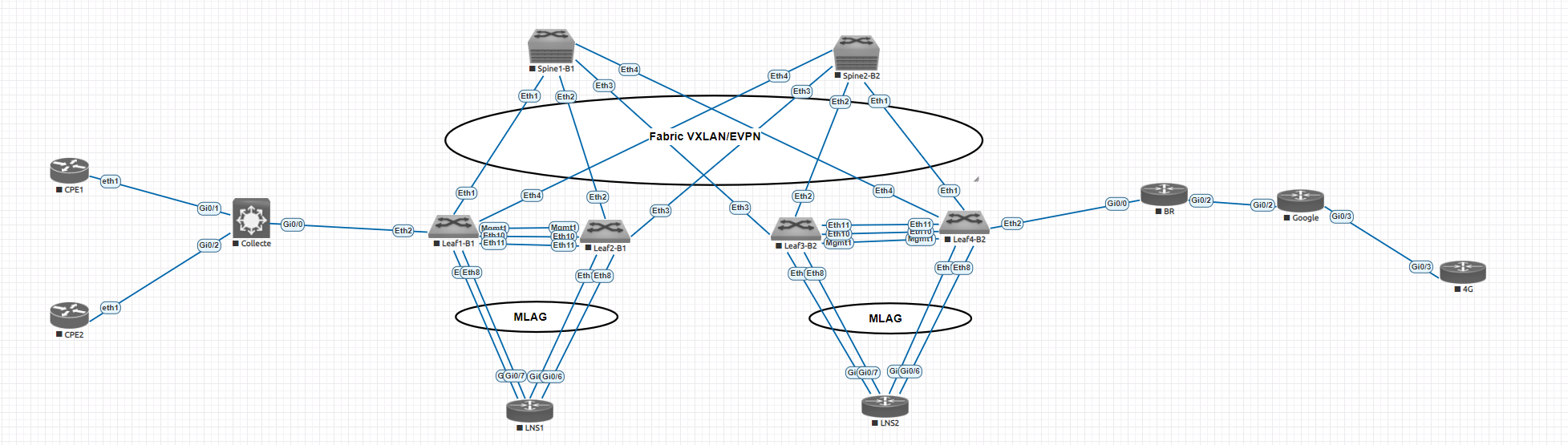
Pour rappel, l'architecture utilisée est celle ci :
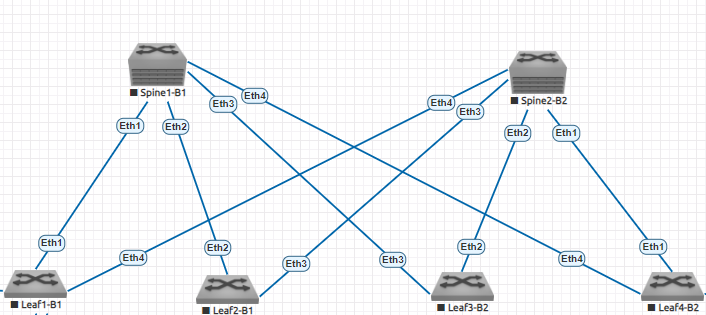
4 leaf et 2 Spines. La seule limite au nombre de leaf serait le nombre de ports sur un spine.
Nos routeurs MPLS seront branchés sur les leafs. Cependant, pour des questions de redondances et se prémunir de la perte d'un leaf (ici, on virtualise donc aucun problème mais les pannes peuvent être présentes dans des datacenters), on va utiliser du MLAG (Multi-chassi Link Aggregation Group). C'est le protocole standard, on retrouve le vPC côté Cisco.
Admettons ce schéma :
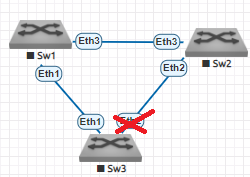
Le lien entre le Sw3 et le Sw2 est bloqué dû à spanning-tree.
Et si, pour le Sw3, le Sw1 et le Sw2 était logiquement le "même" ?
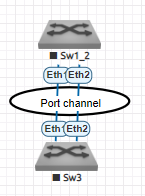
Plus de problème de spanning-tree. J'ai volontairement ajouté deux ports qui forment un Port-Channel. C'est un schéma logique, physiquement il y aura toujours les deux switchs. Sur Sw3, un lien sera branché sur Sw1 et un autre sur Sw2.
C'est le principe du MLAG : deux switchs forment un seul switch pour l'équipement d'en face.
Et pour que Sw1 et Sw2 sachent qu'ils forment un MLAG, il doit y avoir des liens entre les deux :
- Un pour le Keep-Alive (utilisé pour envoyer des "coucou je suis en vie chef !" à l'autre switch) => Interface de niveau 3 dans une VRF
- Un autre pour le peer link (en réalité deux ports qui forment un Port-Channel) => interface de niveau 2
Si on résume avec un beau schéma :
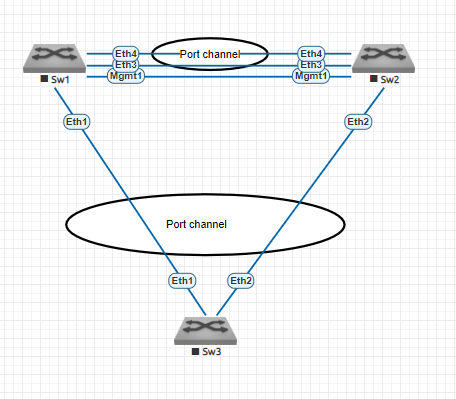
Cette topologie sera donc utilisée mais au lieu du Sw3, il y aura le routeur MPLS avec à la fois sa sortie "IN" et "OUT", chacune en port-channel. Comme ça, on peut se prémunir de la perte d'un leaf. Il faudra préciser dans la configuration du Po sur les Leafs qu'il fait parti du MLAG avec la commande mlag X (où X est un nombre entier et unique).
Allez, on met déjà à jour la topologie :
Enfin bref, encore du blabla depuis le début. Place enfin, à la configuration, à la technique !
On crée un VLAN pour le peer-link avec une IP en /31 et on met une IP sur le port mgmt pour le keep-alive (Arista appelle ça le heartbeat).
#Leaf1
no spanning-tree vlan-id 1-4094
!
vlan 4090
name vlan-peer-link
trunk group MLAG
!
int vlan 4090
ip add 10.0.1.0/31
no autostate
no shut
!
int management1
vrf mgmt
description KEEP-ALIVE MLAG
ip add 10.0.2.0/31
Le trunk group MLAG signifie que le vlan va être autorisé à circuler UNIQUEMENT sur un port précis. Arista nous informe que c'est pour désactiver proprement le spanning-tree sur ce vlan, on s'en fiche un peu vu qu'on va pas du tout l'activer !
Maintenant, on crée le port-channel pour le peer-link qui comprend l'interface et10 et et11 :
#Leaf1
int et10
description PEER-LINK LEAF2 - et10
channel-group 100 mode active
!
int et11
description PEER-LINK LEAF2 - et11
channel-group 100 mode active
!
int po100
description PEER-LINK LEAF2 - po100
switchport mode trunk
switchport trunk group MLAG
Et pour finir, la partie MLAG :
#Leaf1
mlag configuration
domain-id MLAG-Leaf
peer-link po100
local-interface vlan 4090
peer-address 10.0.1.1
no shut
peer-address heartbeat 10.0.2.1 vrf mgmt
dual-primary detection delay 10 action errdisable all-interfaces
Si on compare avec le vPC de Cisco, il faut souligner le fait que le peer-link ait aussi une interco IP. Le heartbeat (équivalent au keep-alive) n'est pas obligatoire. C'est pour avoir plus de sécurité et éviter le split-brain au cas où le peer-link tombe. Idéalement, il doit être séparé du peer-link et dans une table de routage séparé (VRF).
Leaf1-B1#sh mlag detail
MLAG Configuration:
domain-id : MLAG-Leaf
local-interface : Vlan4090
peer-address : 10.0.1.1
peer-link : Port-Channel100
hb-peer-address : 10.0.2.1
hb-peer-vrf : mgmt
peer-config : consistent
MLAG Status:
state : Active
negotiation status : Connected
peer-link status : Up
local-int status : Up
system-id : 52:00:00:cb:38:c2
dual-primary detection : Configured
dual-primary interface errdisabled : False
Le MLAG monte bien. La même configuration sera poussée sur les autres leafs (en changeant les IPs).
Underlay eBGP
On va enfin pouvoir s'attaquer au sujet initial de cet épisode ! Pour rappel, pour créer l'underlay, on doit mettre en place :
- Interco Leaf/Spine
- eBGP entre Leaf/Spine
Dans notre architecture, nous avons 2 spines et 4 leafs mais prenons du recul. Pour x spines et n leafs, on va avoir x*n intercos. En l'occurrence, 8 ici. Créer 8 subnets, les mémoriser (grâce à un IPAM) et vérifier leur authenticité serait pas très compliqué mais si la fabric est 10 fois plus grande ? 100 fois plus grande ? Impossible.
Pour se simplifier la vie et surtout car un bon admin réseau est un admin réseau fainéant, on va utiliser un avantage de IPv6 : l'autoconfig.
Leaf1-B1#sh run int eth1
interface Ethernet1
no switchport
ipv6 enable
Pour vérifier la bonne découverte des voisins :
Spine1-B1#sh ipv6 neighbors
IPv6 Address Age Hardware Addr Interface
fe80::5200:ff:fed7:ee0b 0:03:07 5000.00d7.ee0b Et1
fe80::5200:ff:fecb:38c2 0:00:50 5000.00cb.38c2 Et2
fe80::5200:ff:fed5:5dc0 0:00:42 5000.00d5.5dc0 Et3
fe80::5200:ff:fe03:3766 0:03:26 5000.0003.3766 Et4
Leaf1-B1#sh ipv6 neighbors
IPv6 Address Age Hardware Addr Interface
fe80::5200:ff:fe15:f4e8 0:15:52 5000.0015.f4e8 Et1
fe80::5200:ff:fe72:8b31 0:15:52 5000.0072.8b31 Et4
L'interface récupère une IPv6 FE80::/10. C'est une link-local et la particularité de ces IPv6 c'est qu'elles ne peuvent pas être routées donc pas besoin de vérifier leur authenticité vu qu'elles ne seront pas annoncées dans le BGP ! Top n'est ce pas ?
Il existe une méthode avec du BGP en mode écoute sur les Spines, peer avec un range d'interface et tout plein de truc stylés ! On va utiliser celle ci.
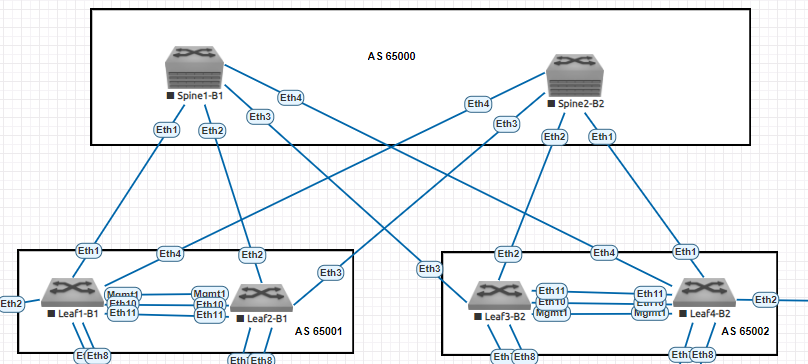
Allez, il faut configurer les sessions eBGP et le tour est joué ! Mais avant ça, il faut définir les loopbacks côté leaf et spine ainsi que les AS. On a commencé en IPv6 donc autant continuer sur cette bonne lancée 😄.
| Switchs | AS BGP | Loopback1 Control Plane | Loopback2 Data Plane |
|---|---|---|---|
| Leaf1 | 65001 | 2001:172:16:1::1/128 | 2001:172:16:2::1/128 |
| Leaf2 | 65001 | 2001:172:16:1::2/128 | 2001:172:16:2::2/128 |
| Leaf3 | 65002 | 2001:172:16:1::3/128 | 2001:172:16:2::3/128 |
| Leaf4 | 65002 | 2001:172:16:1::4/128 | 2001:172:16:2::4/128 |
| Spine1 | 65000 | 2001:172:16:1::10/128 | |
| Spine2 | 65000 | 2001:172:16:1::20/128 |
Pour éviter de tout envoyer en eBGP, on va créer une prefix-list qui autorise uniquement les IPv6 des 2 Loopbacks et on va la placer dans une route-map.
Leaf1-B1#sh run | s prefix-list
ipv6 prefix-list PL_UNDERLAY_LO
seq 10 permit 2001:172:16:1::1/128
seq 20 permit 2001:172:16:2::1/128
Leaf1-B1#sh run | s route-map
route-map RM_UNDERLAY_LO permit 10
match ipv6 address prefix-list PL_UNDERLAY_LO
Ensuite, on configure notre process BGP
Leaf1-B1#sh run | s bgp
router bgp 65001
router-id 172.16.1.1
timers bgp 30 60
bgp default ipv6-unicast
distance bgp 20 200 200
maximum-paths 8 ecmp 16
neighbor GROUP_UNDERLAY peer group
neighbor GROUP_UNDERLAY rib-in pre-policy retain all
redistribute connected route-map RM_UNDERLAY_LO
neighbor interface Et1,4 peer-group GROUP_UNDERLAY remote-as 65000
Par défaut, la distance administrative de BGP dans un Arista est 200 (iBGP / eBGP). Pas dingue, je préfère mettre comme sur un Cisco. eBGP n'intègre pas par défaut l'ECMP, il faut le configurer manuellement. J'ai pris aussi l'habitude de changer les timers des messages BGP pour accélérer le process (message keepalives et hold-time).
En voulant configurer le soft-reconfiguration inboud, il s'est avéré que la commande soit dépréciée par rib-in pre-policy retain. Cependant, même en tapant cette commande, je n'arrive pas à voir quels préfixes sont envoyés et reçus. Il doit me manquer quelque chose mais l'essentiel est là.
Le redistribute connected permet d'annoncer seulement les IPv6 des deux Loopbacks et pour finir, on peer avec un range d'interface ! Trop classe nan ?
Côté Spine, on va utiliser un bgp listen range (coucou Peter) avec le même principe des prefix-list et des peer-group. Le process BGP va se mettre en mode "écoute", c'est à dire qu'il va attendre la demande d'un peer au lieu de l'initier. Petite spécificité, l'utilisation d'un peer-filter qui permet d'autoriser les demandes de peering BGP avec certaines AS spécifiques (les AS des leafs).
Spine1-B1#sh run | s prefix-list
ipv6 prefix-list PL_UNDERLAY_LO
seq 10 permit 2001:172:16:1::10/128
Spine1-B1#sh run | s route-map
route-map RM_UNDERLAY_LO permit 10
match ipv6 address prefix-list PL_UNDERLAY_LO
Spine1-B1#sh run | s peer-filter
peer-filter PF_FABRIC_AS
10 match as-range 65001-65099 result accept
Spine1-B1#sh run | s bgp
router bgp 65000
router-id 172.16.1.10
timers bgp 30 60
bgp default ipv6-unicast
distance bgp 20 200 200
maximum-paths 8 ecmp 16
bgp listen range fe80::/10 peer-group GROUP_UNDERLAY peer-filter PF_FABRIC_AS
neighbor GROUP_UNDERLAY peer group
neighbor GROUP_UNDERLAY rib-in pre-policy retain all
redistribute connected route-map RM_UNDERLAY_LO
Spine1-B1#sh ipv6 bgp summary
BGP summary information for VRF default
Router identifier 172.16.1.10, local AS number 65000
Neighbor Status Codes: m - Under maintenance
Neighbor V AS MsgRcvd MsgSent InQ OutQ Up/Down State PfxRc
fe80::5200:ff:fe03:3766%Et4 4 65002 21 24 0 0 00:11:57 Estab 6 2
fe80::5200:ff:fecb:38c2%Et2 4 65001 24 29 0 0 00:15:12 Estab 4 2
fe80::5200:ff:fed5:5dc0%Et3 4 65002 10 14 0 0 00:05:07 Estab 3 2
fe80::5200:ff:fed7:ee0b%Et1 4 65001 14 16 0 0 00:05:37 Estab 6 2
Spine1-B1#sh ipv6 bgp
BGP routing table information for VRF default
Router identifier 172.16.1.10, local AS number 65000
Route status codes: s - suppressed contributor, * - valid, > - active, E - ECMP head, e - ECMP
S - Stale, c - Contributing to ECMP, b - backup, L - labeled-unicast
% - Pending best path selection
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI Origin Validation codes: V - valid, I - invalid, U - unknown
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthp
Network Next Hop Metric AIGP LocPref Weight Path
* > 2001:172:16:1::1/128 fe80::5200:ff:fed7:ee0b%Et1 0 - 100 0 i
* > 2001:172:16:1::2/128 fe80::5200:ff:fecb:38c2%Et2 0 - 100 0 i
* > 2001:172:16:1::3/128 fe80::5200:ff:fed5:5dc0%Et3 0 - 100 0 i
* > 2001:172:16:1::4/128 fe80::5200:ff:fe03:3766%Et4 0 - 100 0 i
* > 2001:172:16:1::10/128 - - - - 0 i
* > 2001:172:16:2::1/128 fe80::5200:ff:fed7:ee0b%Et1 0 - 100 0 i
* > 2001:172:16:2::2/128 fe80::5200:ff:fecb:38c2%Et2 0 - 100 0 i
* > 2001:172:16:2::3/128 fe80::5200:ff:fed5:5dc0%Et3 0 - 100 0 i
* > 2001:172:16:2::4/128 fe80::5200:ff:fe03:3766%Et4 0 - 100 0 i
Leaf1-B1#sh ipv6 bgp summary
BGP summary information for VRF default
Router identifier 172.16.1.1, local AS number 65001
Neighbor Status Codes: m - Under maintenance
Neighbor V AS MsgRcvd MsgSent InQ OutQ Up/Down State Pc
fe80::5200:ff:fe15:f4e8%Et1 4 65000 59 62 0 0 00:07:48 Estab 75
fe80::5200:ff:fe72:8b31%Et4 4 65000 18 16 0 0 00:07:48 Estab 75
Leaf1-B1#sh ipv6 bgp
BGP routing table information for VRF default
Router identifier 172.16.1.1, local AS number 65001
Route status codes: s - suppressed contributor, * - valid, > - active, E - ECMP head, e - EP
S - Stale, c - Contributing to ECMP, b - backup, L - labeled-unicast
% - Pending best path selection
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI Origin Validation codes: V - valid, I - invalid, U - unknown
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nep
Network Next Hop Metric AIGP LocPref Weight Ph
* > 2001:172:16:1::1/128 - - - - 0 i
* >Ec 2001:172:16:1::3/128 fe80::5200:ff:fe72:8b31%Et4 0 - 100 0 i
* ec 2001:172:16:1::3/128 fe80::5200:ff:fe15:f4e8%Et1 0 - 100 0 i
* >Ec 2001:172:16:1::4/128 fe80::5200:ff:fe72:8b31%Et4 0 - 100 0 i
* ec 2001:172:16:1::4/128 fe80::5200:ff:fe15:f4e8%Et1 0 - 100 0 i
* > 2001:172:16:1::10/128 fe80::5200:ff:fe15:f4e8%Et1 0 - 100 0 i
* > 2001:172:16:1::20/128 fe80::5200:ff:fe72:8b31%Et4 0 - 100 0 i
* > 2001:172:16:2::1/128 - - - - 0 i
* >Ec 2001:172:16:2::3/128 fe80::5200:ff:fe72:8b31%Et4 0 - 100 0 i
* ec 2001:172:16:2::3/128 fe80::5200:ff:fe15:f4e8%Et1 0 - 100 0 i
* >Ec 2001:172:16:2::4/128 fe80::5200:ff:fe15:f4e8%Et1 0 - 100 0 i
* ec 2001:172:16:2::4/128 fe80::5200:ff:fe72:8b31%Et4 0 - 100 0 i
Leaf1-B1#ping ipv6 2001:172:16:1::4
PING 2001:172:16:1::4(2001:172:16:1::4) 52 data bytes
60 bytes from 2001:172:16:1::4: icmp_seq=1 ttl=63 time=6.26 ms
60 bytes from 2001:172:16:1::4: icmp_seq=2 ttl=63 time=3.75 ms
60 bytes from 2001:172:16:1::4: icmp_seq=3 ttl=63 time=3.28 ms
60 bytes from 2001:172:16:1::4: icmp_seq=4 ttl=63 time=3.27 ms
60 bytes from 2001:172:16:1::4: icmp_seq=5 ttl=63 time=5.16 ms
--- 2001:172:16:1::4 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 26ms
rtt min/avg/max/mdev = 3.271/4.343/6.263/1.182 ms, ipg/ewma 6.496/5.301 ms
A partir du Leaf1, l'IPv6 de la Loopback1 du Leaf4 est bien appris par deux chemins différents (par les deux spines). Et le ping fonctionne ! Cependant, je n'apprends pas les loopbacks de Leaf2 (et inversement depuis le leaf1). Par contre, depuis leaf4 :
Leaf4-B2#sh ipv6 route 2001:172:16:1::2/128
B E 2001:172:16:1::2/128 [20/0]
via fe80::5200:ff:fe72:8b31, Ethernet1
via fe80::5200:ff:fe15:f4e8, Ethernet4
Mais pourquoi ?
La réponse est très simple : l'AS est le même entre les deux leafs au sein du MLAG. Leaf1 n'apprendra jamais un préfixe avec un as-path contenant sa propre AS. Logique nan ? C'est pour éviter les boucles de routage ! Il n'y aurait eu aucun problème si le MLAG n'avait pas été présent car chaque LEAF aurait eu une AS différente.
De plus, si une interco entre leaf/spine tombe (problème de jarretières, sfp ou le port), la connexion entre le leaf et les terminaux va toujours fonctionner mais plus de communication avec le reste de la fabric ! Donc comment régler ce souci ?
Underlay iBGP entre les leafs MLAG
Dernier effort et l'underlay sera enfin opérationnel ! Deux solutions possibles :
- mettre l'IPv6 des loopbacks de Leaf1 en secondary sur Leaf2 et vise versa
- établir une session iBGP entre les deux
Je suis parti sur la session iBGP. Un peu plus propre que la secondary. Pour ce faire, soit on crée une nouvelle interco soit on fait circuler un VLAN sur le peer-link. J'ai choisi la deuxième solution.
| Switchs | IBGP vlan 4091 |
|---|---|
| Leaf1 | 2001:172:16:3::/127 |
| Leaf2 | 2001:172:16:3::1/127 |
| Leaf3 | 2001:172:16:3::2/127 |
| Leaf4 | 2001:172:16:3::3/127 |
Leaf1-B1#sh run | s vlan 4091
vlan 4091
name PEER-IBGP-MLAG
trunk group MLAG
interface Vlan4091
ipv6 address 2001:172:16:3::/127
Leaf1-B1#sh run | s neighbor 2001:172:16:3::1
router bgp 65001
neighbor 2001:172:16:3::1 remote-as 65001
neighbor 2001:172:16:3::1 next-hop-self
neighbor 2001:172:16:3::1 description PEER-MLAG-IBGP
Leaf1-B1#sh ipv6 bgp summary
BGP summary information for VRF default
Router identifier 172.16.1.1, local AS number 65001
Neighbor Status Codes: m - Under maintenance
Description Neighbor V AS MsgRcvd MsgSent InQ OutQ Up/Down State PfxRcd PfxAcc
PEER-MLAG-IBGP 2001:172:16:3::1 4 65001 16 14 0 0 00:04:07 Estab 8 8
Leaf1-B1#sh ipv6 route
B I 2001:172:16:1::2/128 [200/0]
via 2001:172:16:3::1, Vlan4091
B I 2001:172:16:2::2/128 [200/0]
via 2001:172:16:3::1, Vlan4091
Leaf1-B1#ping ipv6 2001:172:16:2::2
PING 2001:172:16:2::2(2001:172:16:2::2) 52 data bytes
60 bytes from 2001:172:16:2::2: icmp_seq=1 ttl=64 time=0.071 ms
60 bytes from 2001:172:16:2::2: icmp_seq=2 ttl=64 time=0.031 ms
60 bytes from 2001:172:16:2::2: icmp_seq=3 ttl=64 time=0.024 ms
60 bytes from 2001:172:16:2::2: icmp_seq=4 ttl=64 time=0.024 ms
60 bytes from 2001:172:16:2::2: icmp_seq=5 ttl=64 time=0.020 ms
--- 2001:172:16:2::2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 5ms
rtt min/avg/max/mdev = 0.020/0.034/0.071/0.018 ms, ipg/ewma 1.184/0.051 ms
Rien de bien compliqué dans le process BGP. Il faut juste penser à indiquer le next-hop-self car en iBGP, le next-hop ne change pas !
Allez on applique la configuration sur les autres leaf et on peut enfin dire que l'underlay est FINIE.
Regardez, ça fonctionne en plus ! Si on shut les interfaces côté spine de Leaf1 et qu'à partir de Leaf4, on ping la loopback de Leaf1, le paquet passe par Spine2, Leaf2 et Leaf1 !
Leaf4-B2#traceroute 2001:172:16:1::1
traceroute to 2001:172:16:1::1 (2001:172:16:1::1), 30 hops max, 80 byte packets
1 2001:172:16:1::20 (2001:172:16:1::20) 8.775 ms 9.144 ms 10.256 ms
2 2001:172:16:1::2 (2001:172:16:1::2) 14.892 ms 15.498 ms 16.785 ms
3 2001:172:16:1::1 (2001:172:16:1::1) 21.765 ms 25.604 ms 26.446 ms
Conclusion
Gros épisode aujourd'hui. Habituellement, l'underlay est rapide à configurer si on fait de l'OSPF ou de l'IS-IS. J'ai décidé de me compliquer un peu la vie mais ca fait classe comme ça maintenant.
Le MLAG apporte des contraintes supplémentaires en terme de configuration mais aussi pour le débug. Cependant, ce protocole offre une grande redondance. La perte d'un leaf sera, certes visible et impactant, mais le temps de convergence est relativement court (quelques tests m'ont permis de constater la perte de ping seulement pendant 1-2 secondes, à voir ce que ca donne avec du matos physique). On pourrai utiliser le protocole BFD pour diminuer encore plus, peut être dans un autre épisode. Un peu déçu sur le fait de pas pouvoir configurer le MLAG en IPv6 par contre.
La fabric avance bien ! Prochain épisode, place à l'overlay.
Je termine sur un petit mot de fin : Lisez Boruto 🥷🥷