
C'est quoi ça encore ? Pourquoi pas un NAS avec un partage de fichier ?
Un NAS est un serveur de fichier en NFS/SMB par exemple sur le réseau IP. Il est simple à mettre en place mais ne convient pas forcément à nos besoins. En effet, ce n'est pas très performant et c'est un gros SPOF ! Si le serveur plante, le stockage plante.
Le SAN est un stockage au niveau bloc. En gros, cela permet que chaque serveur voit l'espace disque d'une baie SAN auquel il a accès comme son propre disque dur. Ce n'est pas de l'IP, il se base sur de FiberChannel / iSCSI. Comme dit plus haut, c'est une baie, cela permet d'avoir de la redondance. Mais le gros point négatif, c'est que j'y pige rien et ça coûte cher (le matos, les licences et les baies à mettre dans le datacenter).
L'hyperconvergence permet de rassembler le réseau, la virtualisation et le stockage sur un seul point donc plus de baie de stockage, plus de serveur de stockage. Les nodes dans le cluster proxmox vont être membre du stockage. En gros, si on souhaite avoir plus de stockages, on rajoute des disques dans les serveurs et c'est parti.
Bref vous l'aurez compris, je ne suis pas expert stockage. Mon but est de faire un backbone stylé donc j'ai choisi du CEPH (Hyperconvergence) pour le cluster de proxmox. La configuration est très simplifiée car elle se fait en GUI. Le plus important est le dimensionnement des ressources du cluster. La doc de proxmox pour l'implémenter est juste en dessous :
Un peu de vocabulaire :)
- OSD : Disque dans ceph
- MON : Ceph monitor, il maintient une carte du cluster. C'est à dire qu'on va pouvoir voir, sur une seule interface, les OSD, etc.
- MGR : Ceph manager, il permet d'avoir des métriques, de fournir une API REST
- Public network : C'est le réseau que vont utiliser les VM quand l'utilisateur va créer un fichier (par exemple)
- Cluster network : C'est le réseau que vont utiliser les nodes Ceph pour le rebalancing des OSD s'il y en a qui sont supprimés/ajoutés, la réplication d'OSD, etc
Ceph est très gourmand en ressources ! Idéalement, je souhaiterai avoir un cluster de 5 R630 avec 20 cores / 128 Go RAM / 4*2To SSD et 4 ports 10G + 2 ports 40G :
- 2*10G pour l'accès internet de VM et le corosync du cluster
- 2*10G pour le front end CEPH (public network)
- 2*40G pour le back end CEPH (cluster network)
Malheureusement, joie du lab (ou pas), je suis obligé de tester en virtualisé donc les performances ne seront pas présentes. Par exemple, je mutualise le réseau public et cluster ceph sans LACP (très mauvaise pratique !!!)
Installation
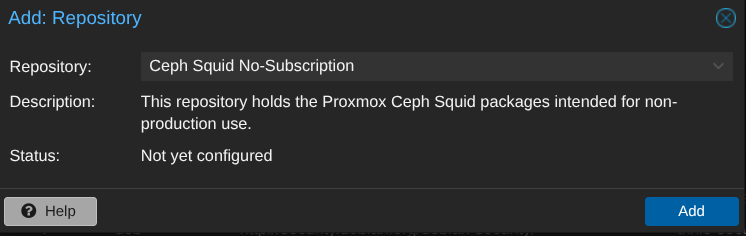
Il faut ajouter les dépôts gratuits de ceph sur les nodes :
Comme évoqué au dessus, proxmox permet de l'installer en GUI :
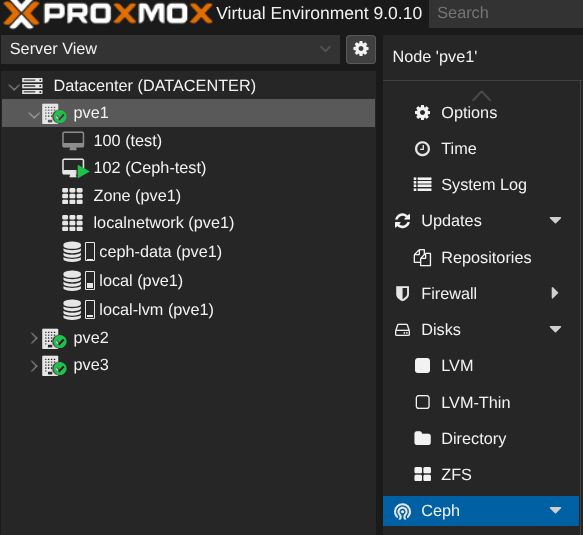
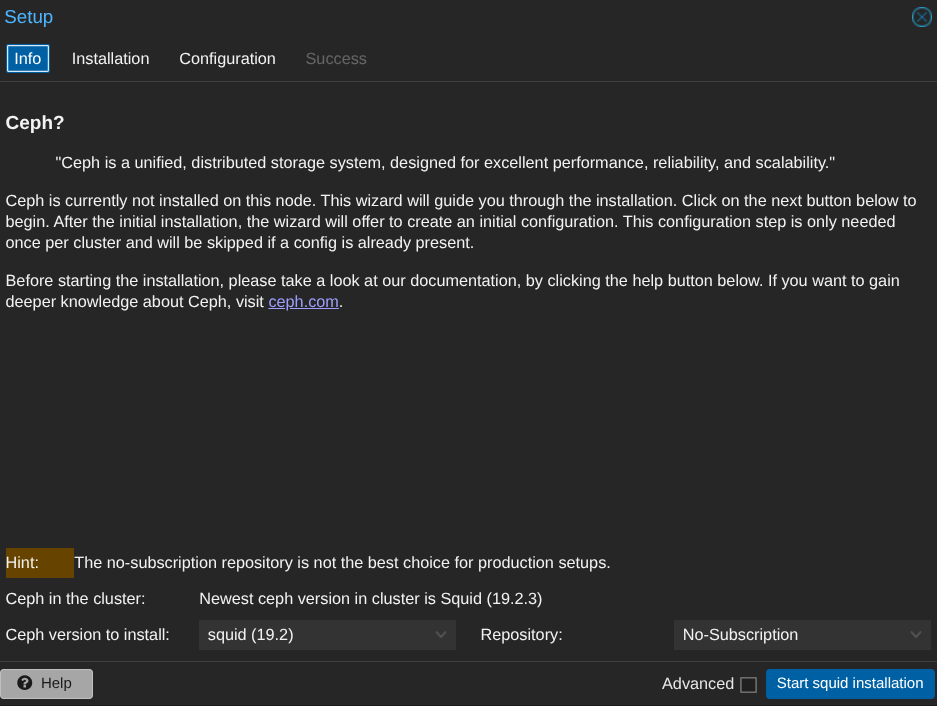
Le cluster ceph se fait sur un réseau différent sur une carte réseau différente (minimum 10G). Le réseau est 100.77.1.0/24 où .51 est PVE1, .52 PVE2 et .53 PVE3.
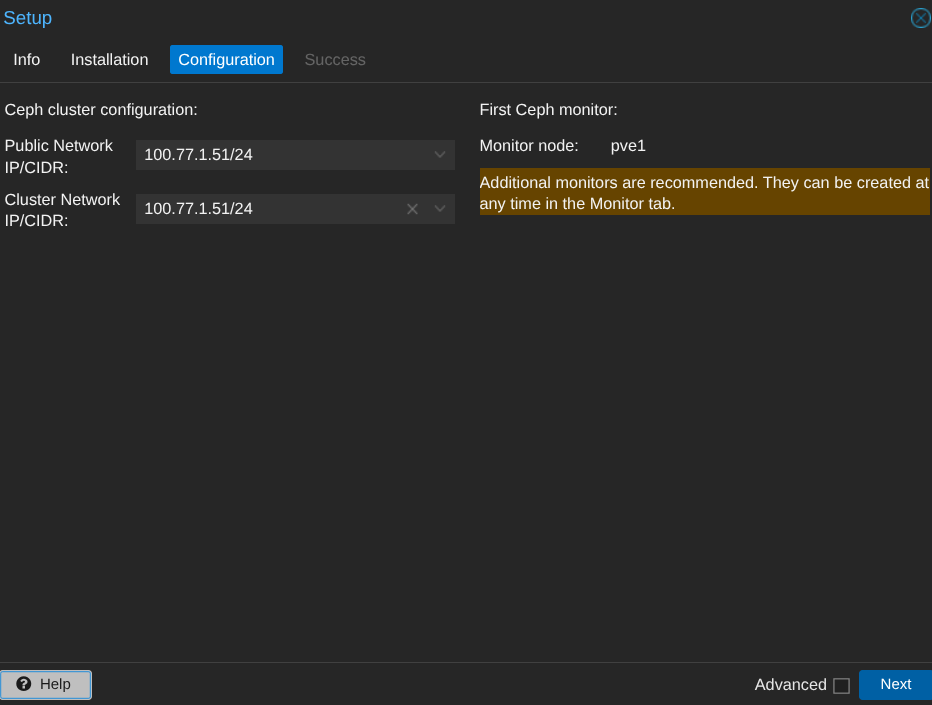
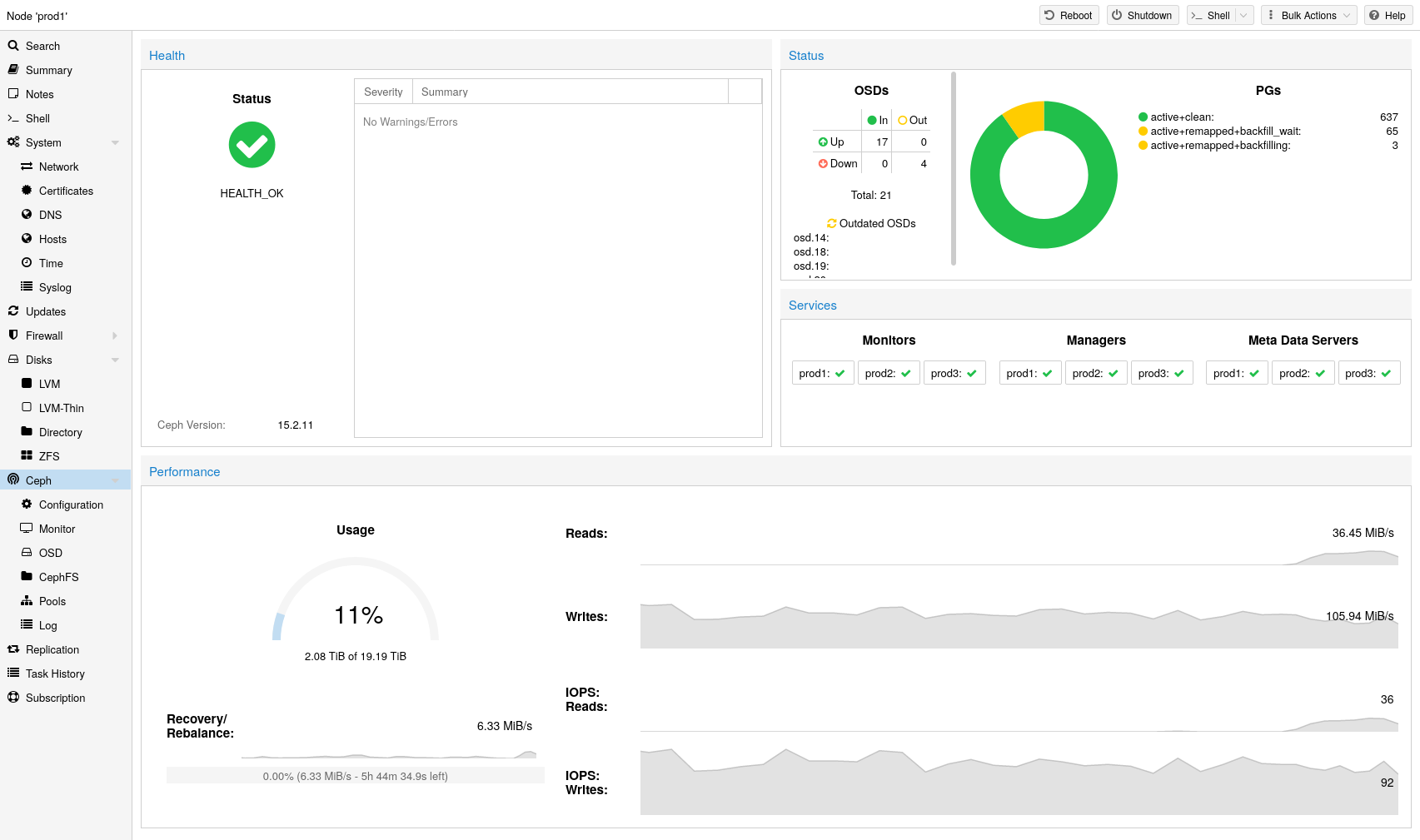
Ceph est installé mais j'ai un warning, pourquoi ?
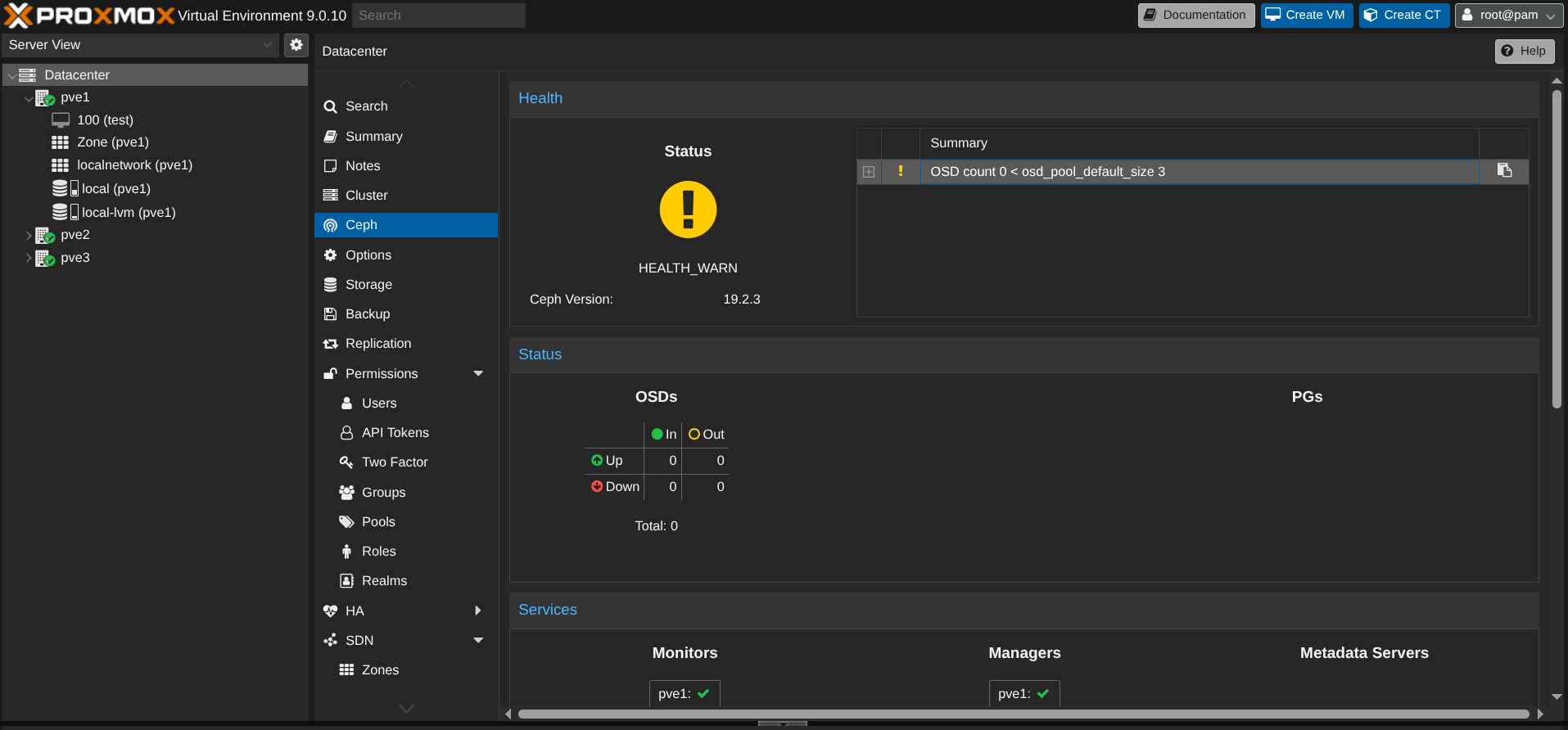
Car je n'ai pas encore d'OSD (de disques) dans CEPH.
Ensuite, on fait les mêmes étapes sur PVE2 et PVE3 sauf la configuration qui est déjà initialisée (via l'installation sur PVE1).
Une fois le cluster configurée, nous pouvons créer les OSD. J'ai 4 disques de 20Go (c'est du lab !!!) sur chaque node :
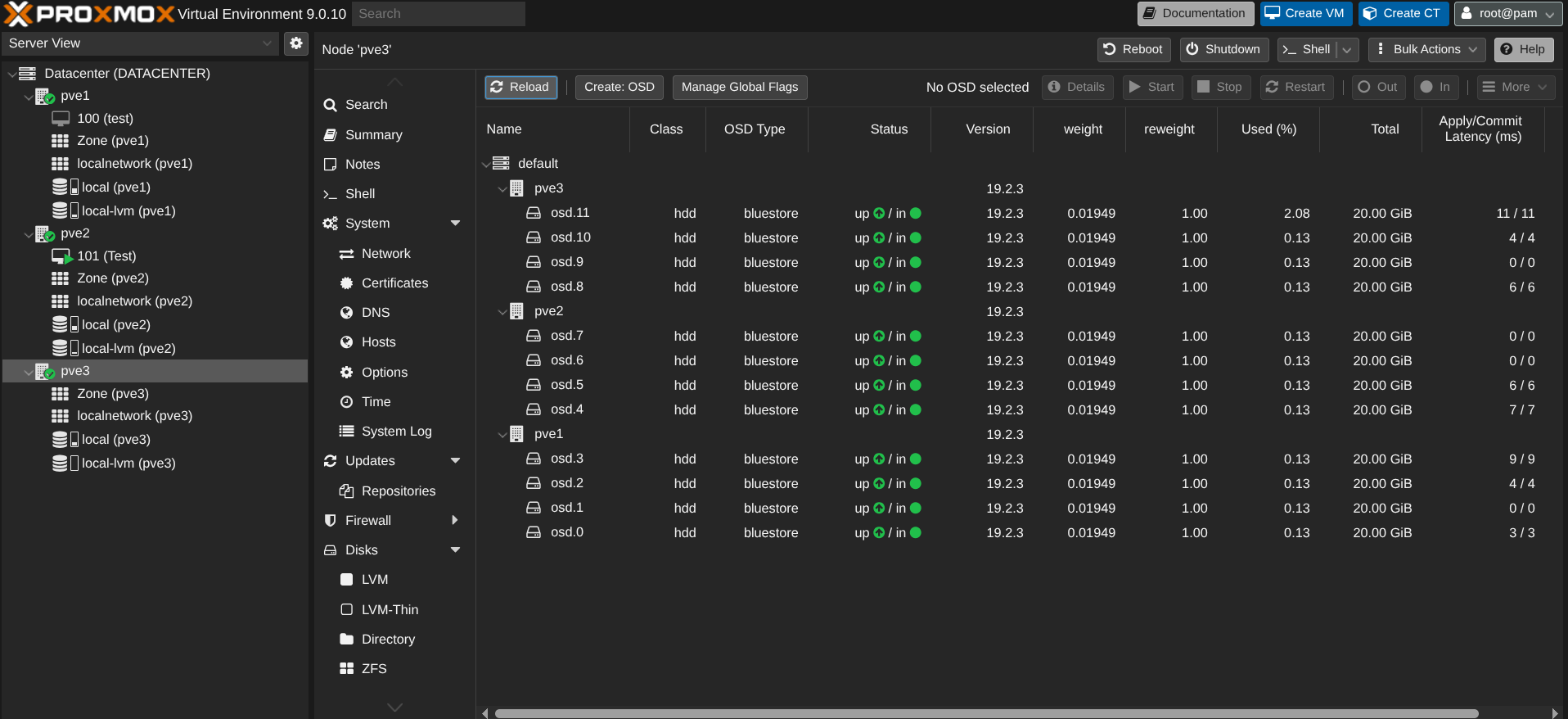
Chaque node est monitor et PVE1 est le manager principal, ensuite s'il plante, c'est PVE2 puis PVE3.
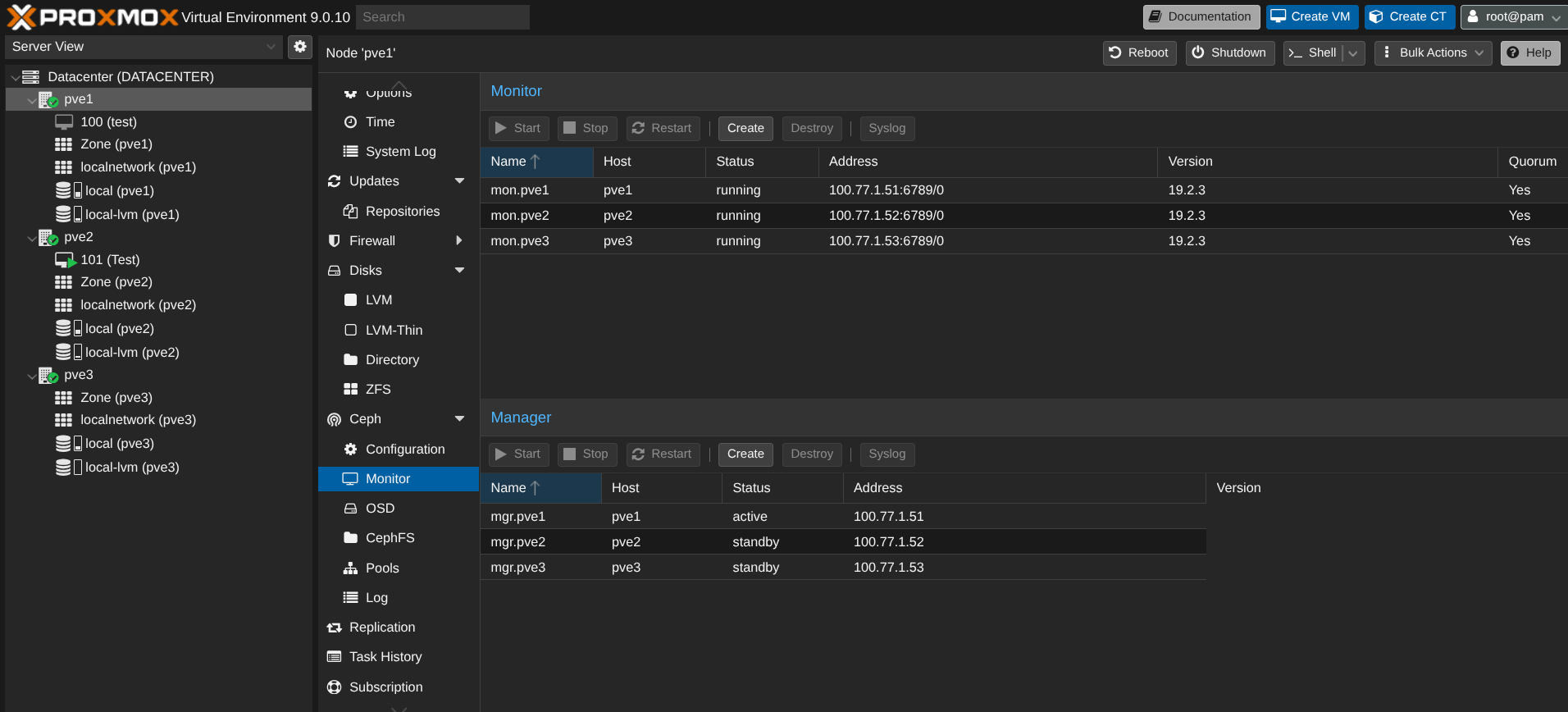
Ensuite, on crée le pool CEPH (pour que les VM puissent être configurées dans ce pool de stockage) :
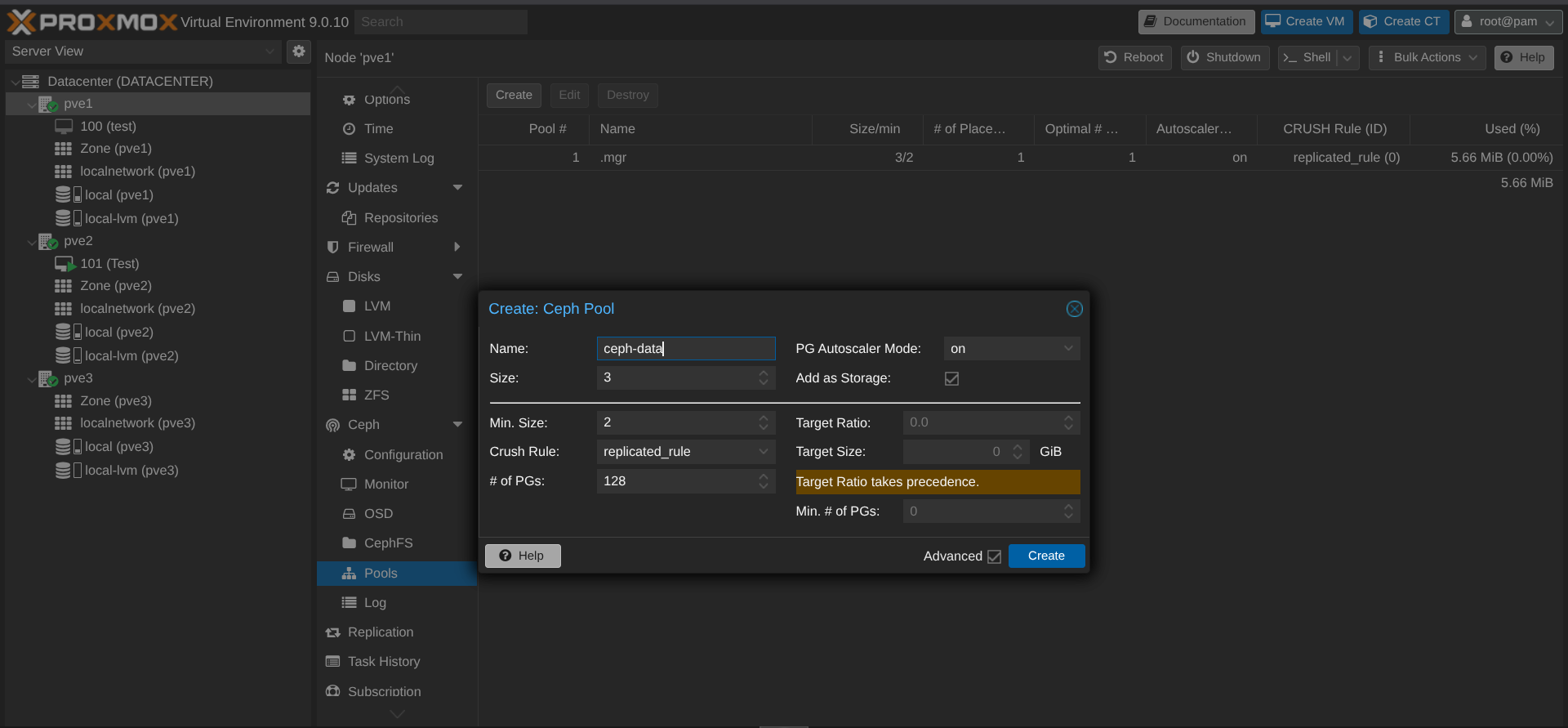
On peut voir que j'ai 240Go de disponible sur le stockage.
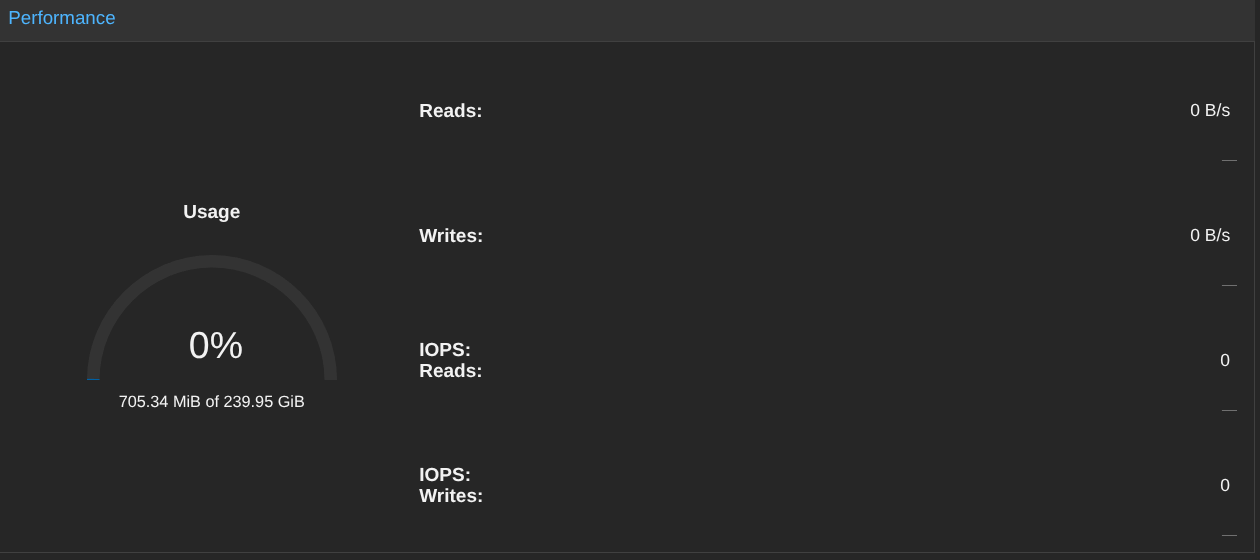
Sauf que, par défaut, Ceph fait 3 copies de chaque données (1 copie par node) donc 240/3 = 80 Go max. Je ne perds pas les 160 Go de stockage, juste ils vont permettre aux VM d'avoir une copie de leur données sur un autre node. Ainsi si un PVE tombe, les VM vont basculer sur un autre node sans risque de perdre les données car répliquées sur un autre node 😄
Prenons exemple d'une VM de 16Go sur PVE1 :
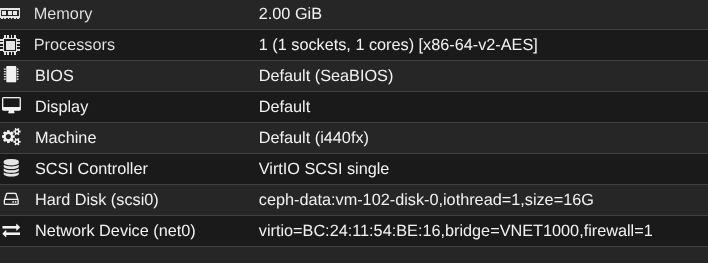
Chaque disque est utilisé :
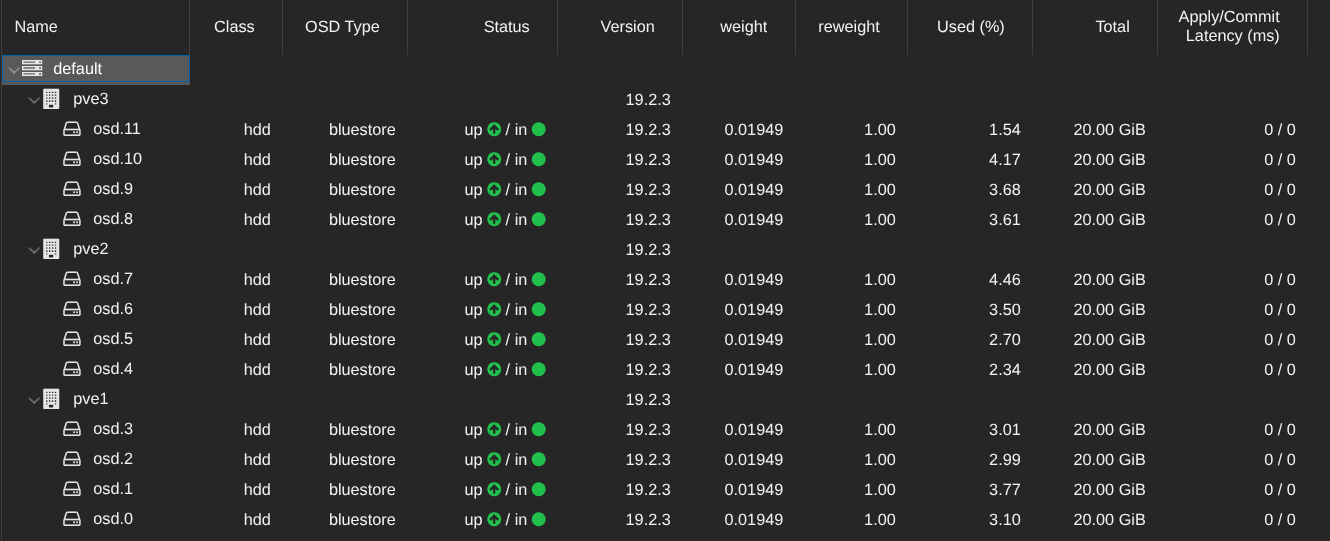
On est plutôt pas mal ! Maintenant, on va essayer la migration à chaud (avant on met une IP 10.0.0.10/24 pour faire un test de ping en continu pendant la migration).


Je lance la migration avec un ping en continu sur la VM :
sent=1219 received=1219 packet-loss=0% min-rtt=2ms812us avg-rtt=9ms686us max-rtt=137ms328us
Aucune perte de ping pendant la migration et la VM est UP sur PVE2 :
Et si un node plante ? Il faut d'abord penser à créer une règle comme quoi la VM peut reboot sur un autre node :
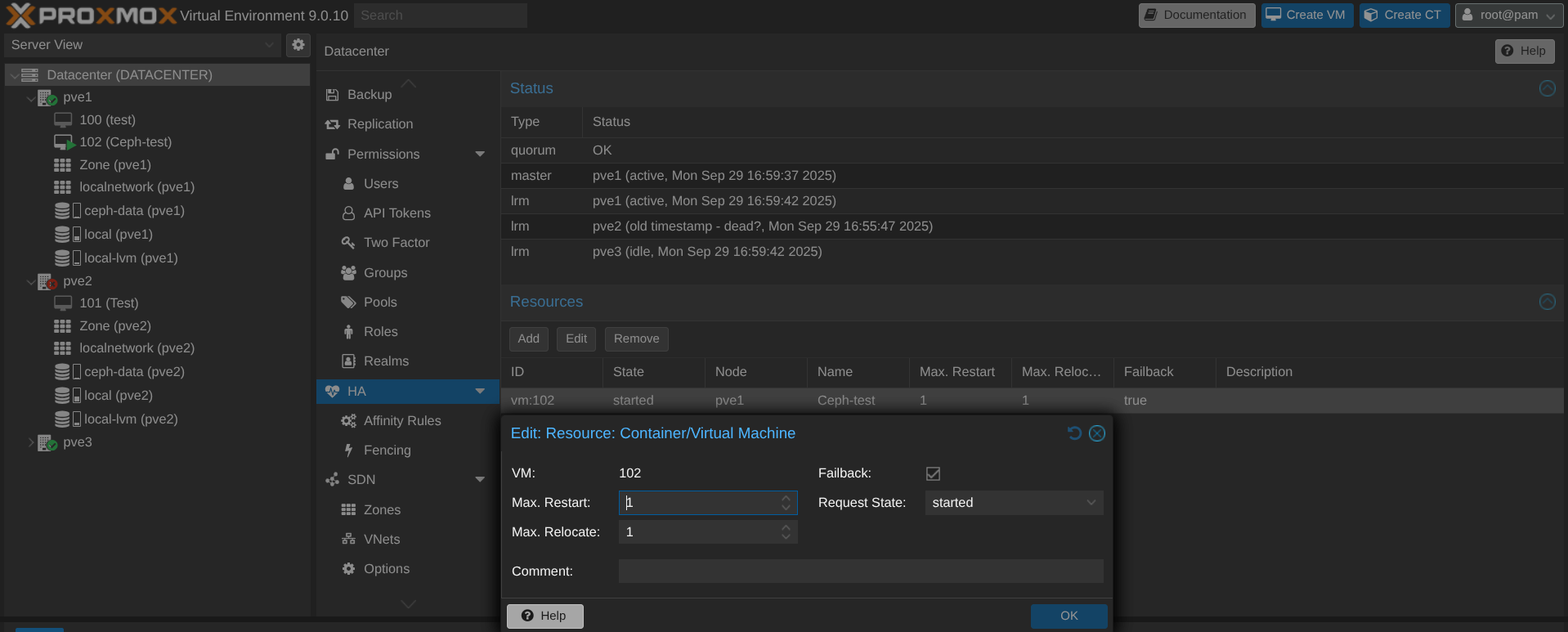
Le PVE2 est down, la VM reboot bien sur PVE1 ! Dans les logs du cluster :
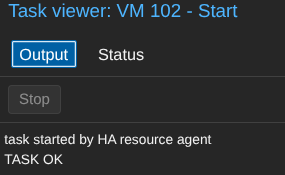
Comparé à la migration à chaud, la VM reboot donc il y a un impact en production mais cela reste minime au vu du problème initial : la perte d'un node.
Conclusion
L'infra hosting est presque terminée ! Manque plus encore deux petites choses que je vais développer dans le prochain épisode.
Même si je n'ai pas la totale expertise sur le cluster (admin réseau ici), il est bien paramétré, le réseau EVPN/VXLAN dans la fabric Arista est opérationnel et le stockage ceph aussi.
Idéalement, ça serait sympathique de partir sur un cluster de 5 R640, 2*20 Core, 128Go RAM, 4*10Gbps NIC, 2 NIC de 40G, 4 SSD 2To et 2 SSD 256Go (en zfs pour l'OS). Cela permettrait d'être tranquille si jamais un node venait à planter mais bon, money money ...
On a vu un peu d'automatisation l'épisode précédent pour la création des VNI/Interfaces sur les PVE. Je vais attendre de monter l'infra devops pour m'attaquer à la création automatique des VM clientes (de l'ansible ou du terraform à voir :p)
Je termine sur un mot de fin : Vivement 2027 ...