
Est ce vraiment important le cluster ?
Imaginons, nous proposons des solutions virtualisées à nos clients (AD/TOIP/MAIL et autre), on pourrait très bien configurer les VM sur plusieurs PVE indépendants des autres. Cependant, si un PVE plante, toutes les VM sur ce node sont foutues... Avec une GTR 4H, dur de remonter les services en bonnes heures !
Avec un cluster de PVE, si un tombe, les VM basculent automatiquement sur les autres nodes. Bien sûr, il faut faire attention à la partie réseau (les interfaces VXLAN doivent être disponibles sur chaque PVE) et le stockage (NAS/SAN/ZFS ou CEPH).
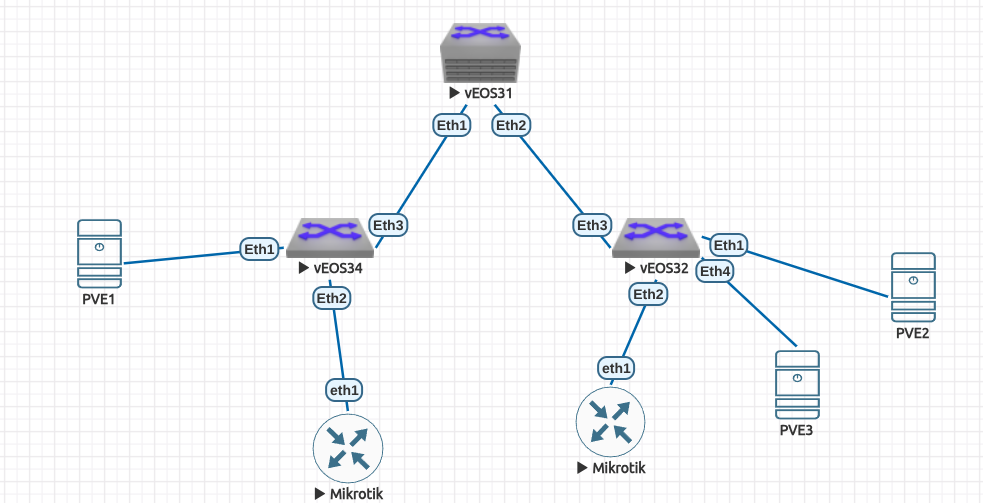
Dans cet épisode, on regarde la partie réseau. On monte un cluster de 3 PVE dans une fabric EVPN/VXLAN Arista 😄 (Bien sur, plus il y a de PVE mieux c'est !)
Configuration
Pour commencer, il faut que chaque PVE soit dans la même version proxmox. Avec la commande pveversion, on peut voir que j'ai monté mon cluster dans la version 9.0.10 (la plus récente à l'heure où j'écris).
root@pve1:~# pveversion
pve-manager/9.0.10/deb1ca707ec72a89 (running kernel: 6.14.8-2-pve)
On monte les sessions BGP EVPN entre les nodes et les leafs (172.16.1.51 = PVE1, 172.16.1.52 = PVE2 et 172.16.1.53 = PVE3). Les configurations sont sur mon github (du vu et du revu l'EVPN sur Arista 😄). Les PVE arrivent bien à communiquer avec les loopbacks de autres.
root@pve1:~# ping 172.16.1.52 -c 1
PING 172.16.1.52 (172.16.1.52) 56(84) bytes of data.
64 bytes from 172.16.1.52: icmp_seq=1 ttl=61 time=4.88 ms
--- 172.16.1.52 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 4.875/4.875/4.875/0.000 ms
root@pve1:~# ping 172.16.1.53 -c 1
PING 172.16.1.53 (172.16.1.53) 56(84) bytes of data.
64 bytes from 172.16.1.53: icmp_seq=1 ttl=61 time=4.62 ms
--- 172.16.1.53 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 4.621/4.621/4.621/0.000 ms
On crée le cluster sur PVE1 :
root@pve1:~# pvecm create DATACENTER --ring0_addr 172.16.1.51
On renseigne dans le fichier hosts des PVE, les FQDN des autres PVE du cluster :
root@pve1:~# cat /etc/hosts
127.0.0.1 localhost.localdomain localhost
172.16.1.51 pve1.naruto.ninja pve1
172.16.1.52 pve2.naruto.ninja pve2
172.16.1.53 pve3.naruto.ninja pve3
On a a plus qu'à faire rejoindre PVE2 et 3 dans le cluster de PVE1 :
root@pve2:~# pvecm add pve1.naruto.ninja
root@pve3:~# pvecm add pve1.naruto.ninja
En GUI, on peut voir nos trois nodes. Ils sont manageables depuis une interface.
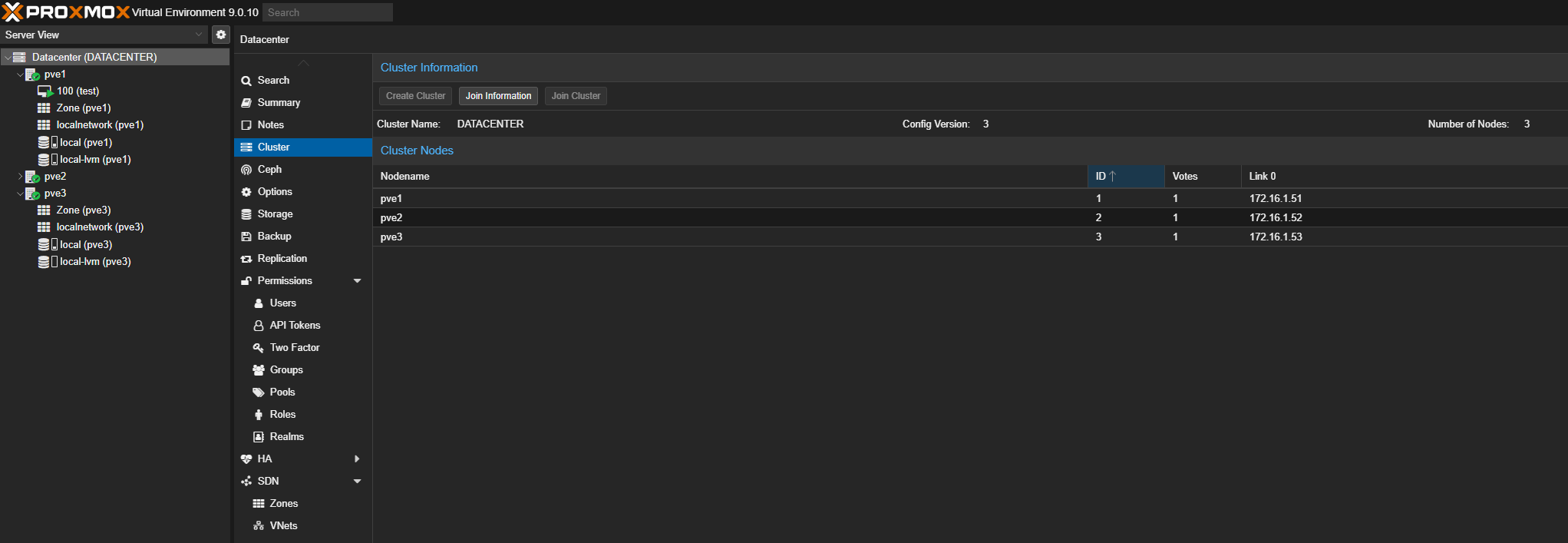
Bon c'était pas trop compliqué ! J'aurai pu avoir 5 voir 7 nodes mais les limitations d'un homelab ! On aime bien avoir un nombre impair de PVE pour avoir le quorum.
Migration VM
Comme je voulais l'avait dit, le but d'un cluster est d'avoir une mutualisation des ressources. On peut donc s'amuser à migrer des VM entre nodes par exemple :
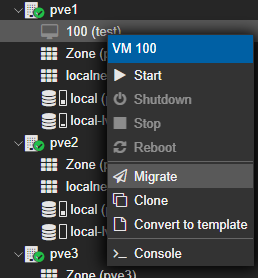
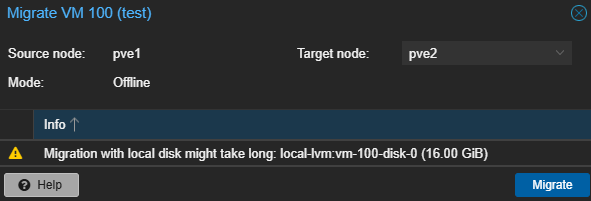
Cependant, sans stockage partagée, proxmox nous informe que la migration peut prendre beaucoup de temps car il va copier les 16Go de données de la VM sur l'autre PVE :
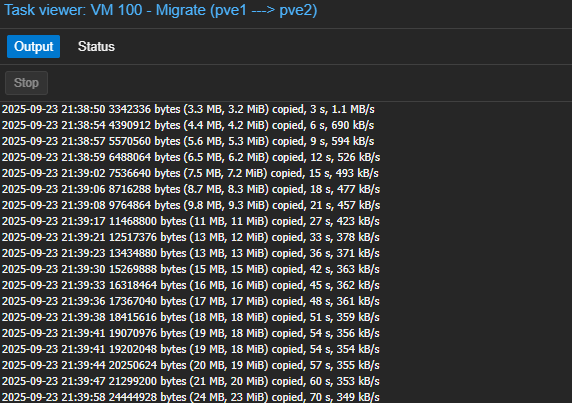
Le débit est clairement pas ouf (dans le cas de ce blog, c'est du VXLAN dans du VXLAN avec des arista virtualisés dans EVENG ... Autant vous dire que la bande passante est pas folle mais ça fonctionne !) Sur des intercos 100G, la migration prendrait quelques secondes ! Mais ce qu'on souhaite par dessus tout, c'est que la migration se fasse instantanément grâce à un SAN ou CEPH. (Programme du prochain épisode)
On va créer une VM sur PVE2 avec le VNET1000 (bien sur il faut créer l'interface sur tous les nodes !) :
On met une IP dans le réseau 10.0.0.0/24 (réseau de test avec les Mikrotik faisant office de PE et la VM de test de l'épisode précédent) :
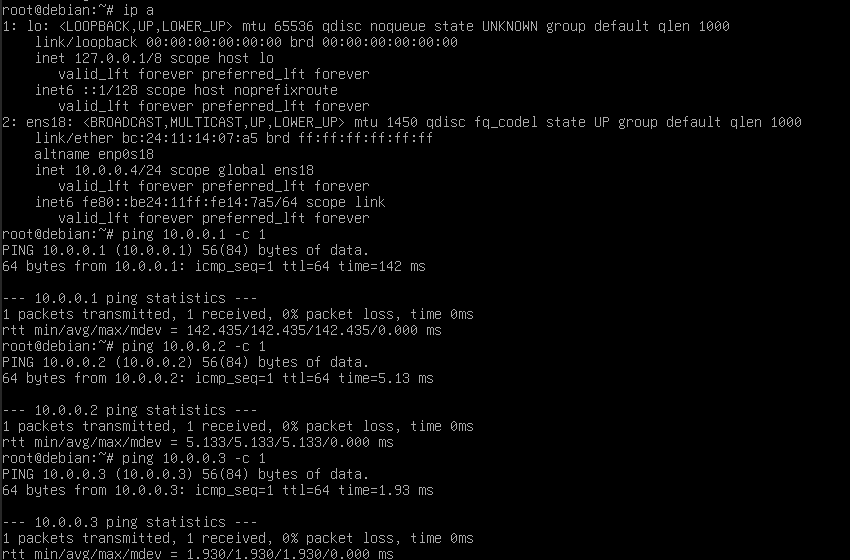
Ça ping ! La L2VNI est bien diffusée dans la fabric 😄
Et si jamais un node reboot ? J'observe quelques secondes le temps qu'il soit de nouveau opérationnel (le temps que mes sessions BGP remontent !)
Automatisation
Bah oui ! Réfléchissons au début pour voir comment on pourrait standardiser la production et l'exploitation de la partie hosting.
Pour chaque réseau client, on doit crée une interface VXLAN et un bridge dans le fichier /etc/network/interfaces. De plus, on doit diffuser la VNI avec le FRR (le RD peut être différent mais il faut avoir le même RT dans toute la fabric). On va regarder comment on peut faire ça en ansible !
Le code ansible est dispo sur mon github. Au final pour créer une nouvelle VNI sur le cluster (FRR et Interfaces), je lance la commande :
ansible-playbook -i hosts playbook/new_vni.yml -e vni_id=3001
Pour l'instant, mes codes sont disponibles uniquement en CLI sur une machine faisant office de rebond mais une fois l'infra virtualisation et voix opérationnel, je m'attaque à l'infra devops (Gitlab/AWX/Jenkins/Netbox).
Conclusion
Le cluster est opérationnel d'un point de vue réseau. On l'a bien vu pendant la migration de la VM : ça prend énormément de temps ! Et la réponse est toute simple : car le stockage n'est pas partagée entre les nodes.
C'est à dire que les données des VM sont uniquement sur le PVE où est physiquement la VM. Si migration, toute la data de la machine doivent être migrés sur l'autre node. Autant dire que quelques gigaoctets, pourquoi pas, mais si j'ai 100 VM sur un nœud et qu'il plante ... mamacita.
Prochain épisode : on règle ce problème en implémentant la solution ceph pour du stockage hyperconvergé !
Je termine sur un mot de fin : je ne recherche plus de travail